中國網/中國成長門戶網訊 在曩昔的幾個世紀中,性命迷信一向處于疾速成長和演化的階段,從最後對性命景象的簡略察看和描寫,到現在分子生物學、基因組學和體系生物學等範疇的鼓起,性命迷信研討范式連續演化。這種研討范式的變更深受生物數據類型和範圍的成長所推進,并帶來了性命迷信成長演進的3個階段(圖1)——每個階段都在前一個階段的基本上遞進,不竭涌現新的技巧和方式來疾速推進性命迷信研討的不竭提高。
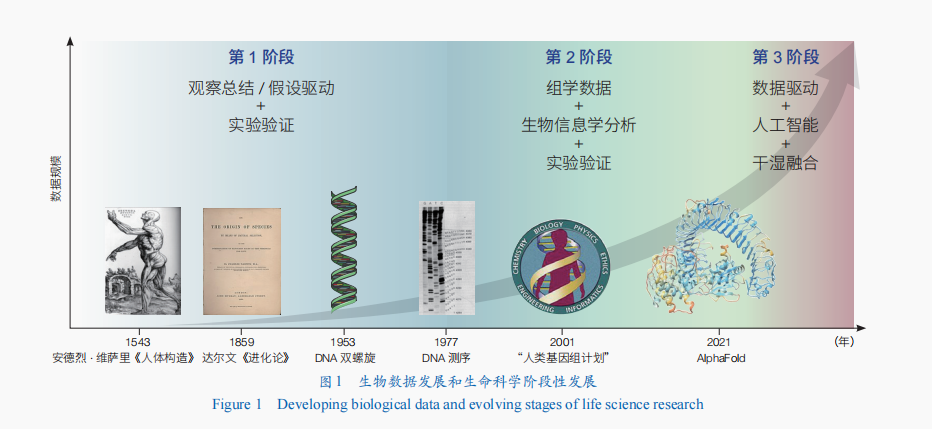
第1階段(16世紀—20世紀下半葉):以察看總結和假定驅動為主,試驗數據作為幫助支撐和驗證根據。在晚期,生物學家重要依附手工試驗和察看描寫獲取數據,并從中提煉回納出一些假說。但這些數據凡是是概況的、部分的、無限的,發生的假說也是微觀和粗略的,無法對性命的深層機制停止解析。其緣由在于認知程度和技巧的限制招致無法取得息爭析更深條理的生物學數據。這一時代的性命迷信研討的典範代表有:16世紀的安德烈·維薩里經由過程植物和人體的剖解數據周全熟悉機體構造;19世紀,達爾文經由過程舉世考核采集和剖析大批標本數據提出退化論等。其后,跟著物理學、化學等學科的成長,以及試驗技巧和剖析方式的疾速提高,尤其是DNA雙螺旋構造的發明和中間包養行情法例的提出,將性命迷信研討引進分子生物學時期。生物學家可以將復雜的性命體系拆解為微不雅的分子和細胞組分并逐一停止研討,以取得對生物體系單一維度、深條理的描寫數據。研討職員凡是采用主動剖析的方式,即依據事前提出的假定來遍歷息爭釋試驗數據,此時構成的是對性命體系深刻卻零碎、單方面的認知。
第2階段(20世紀下半葉—21世紀初):以組學數據為基本,聯合生物信息學剖析和試驗驗證。測序技巧的呈現和“人類基因組打算”的實行將性命迷信引進了高通量生物研討時期。基因組學、轉錄組學、表不雅組學、糖組學等多種組學技巧浮現了細胞在分歧層面的全體性命圖景。生物學家可以或許在晚期發育、癌癥、朽邁、疾病等多個性命經過歷程中停止高通量、年夜範圍的數據采集。此時,他們不再局限于驗證特定的假定,而是經由過程多種組學數據來摸索未知範疇。多組學數據的剖析需求更復雜的盤算東西和算法,包含生物信息學、統計學等。這些東西和方式輔助研討職員從海量數據中發明暗藏的形式和聯繫關係,從而取得更周全、更深刻的生物學常識。別的,應用生物信息學對組學數據剖析取得的常識還需求應用濕試驗停止驗證。盡管這一階段可以或許對生物學數據停止低維度的描寫息爭釋,卻難以對復雜的性命體系停止高維度模仿,以完成對性命的周全體系解析。
第3階段(21世紀初至今):以生物年夜數據驅動,應用人工智能和干濕融會對性命體系停止解析與重構。性命體系浮現分子、細胞、組織、個別等多條理的構造,并且這些條理之間高度互聯、靜態調控,構成了一個復雜的體系;而由此取得的數據也具有多條理、靜態變更的特色。此外,跟著性命迷信研討的不竭深刻,海量的多組學數據、文獻材料和其他生物學數據連續涌現和積聚,從而招致數據範圍和復雜性進一個步驟增添。這種多類型、多維度且體量宏大的生物學數據被稱為生物年夜數據。但是,傳統的數據剖析方式曾經無法知足處置這一復雜性的需求。針對分歧條理、分歧維度、分歧類型的生物年夜數據停止有用整合、匯集和深刻剖析,以提醒此中包含的高維度生物紀律,成為當此生命迷信研討面對的挑釁之一。人工智能,尤其是神經收集技巧,因其善於從低維度的年夜範圍數據中提取高維度藏匿紀律的上風成為處理這一挑釁的有用東西。例如,AlphaFold可以或許猜測卵白質的三維構造,GeneCompass等東西能模仿基因調控收集。這些東西和技巧證實了應用人工智能可以發掘生物年夜數據中數據之間的聯繫關係,抽提性命的內涵構造,從而更周全地輿解性命景象的實質和紀律,提醒生物體外部復雜的互動關系和調控機制。但是,以後人工智能技巧依然僅能有用整合、剖析某一層面的生物數據(如轉錄組)。要完成對復雜互聯的性命體系停止周全、體系和深入的認知,需求積聚更多的體系性生物年夜數據,并應用人工智能技巧對多模態的生物年夜數據停止有用整合,以完成對性命體系全體圖景的認知。並且,人工智能領導的主動化機械人曾經完成了在化學和資料學上自立design、計劃和履行真正的世界的試驗,從而明顯進步了迷信發明的速率和多少數字,并改良了試驗成果的可復制性和靠得住性。將來應用生物年夜數據練習的人工智能聯合主動化機械人,將能夠樹立干濕融會的自退化研討新范式,以完成對更復雜的性命體系停止更高效和更深刻的解析。
綜上,生物學數據推進性命迷信成長經過的事況了包養網從察看總結和假定驅動為主、組學數據為基本到生物年夜數據驅動的3個遞進階段。在這個經過歷程中,生物學數據浮現範圍遞增、類型豐盛和條理加深的特色,也推進了對性命實質的認知從對性命體系微觀總結、性命元件深刻認知、性命體系周全低維度描寫到性命體系解析和重構的不竭深刻。
數據驅動性命迷信研討的內在和特色
數據驅動性命迷信研討的內在表現在其對研討范式、方式論和認知形式的深入影響上。誇大了以數據為焦點的研討方式,將數據的采集和剖析置于中間地位。這意味著研討者不再僅依靠于個體案例或部分景象,而是經由過程搜集年夜範圍、多樣化的生物學數據來推進研討的成長。數據驅動的性命迷信研討具有跨學科性和整合性的特色。跟著技巧的成長和數據的積聚,性命迷信的研討越來越需求跨越分歧學科範疇,如生物學、盤算機迷信、統計學等,停止數據的整合和剖析。數據驅動的性命迷信研討側重于量化生物景象,并試圖將其體系化地輿解。傳統的生物學研討往往是基于定性察看和描寫,而數據驅動的方式則加倍重視經由過程數據搜集、處置和剖析,樹立生物體系的量化模子。這種量化和體系化的方式使得研討者可以或許更周全地輿解性命體系的復雜性,并從中發明暗藏的紀律和聯繫關係。數據驅動的性命迷信研討誇大試驗數據與數字化建模的聯合。經由過程搜集大批的試驗數據,并應用數學模子和盤算方式停止數字化建模,停止高通量、高正確度地猜測和挑選,從而可以高效驗證和修改生物學實際,并提出新的假定和猜測。這種濕試驗與數字化建模聯合的研討方法使得性命迷信研討加倍體系和深刻,推進了生物學常識的不竭提高。
數據驅動性命迷信研討的特征具有3項明顯性特色。生物學數據具有多樣性和豐盛性的特色。生物數據涵蓋了生物體系的各個條理和多個方面——從基因組序列到卵白質構造,再到細胞效能和生物表型,生物學數據包括了豐盛的信息,為研討者供給了深刻摸索性命景象的基本。生物學數據具有高維度和年夜範圍的特色。跟著技巧的提高,生物學數據的維度和範圍不竭增添。例如,基因組學和轉錄組學等高通量測序技巧的呈現,使得研討者可以或許同時研討不計其數個基因或基因表達物,從而取得高維度的數據。這種高維度和年夜範圍的數據為研討者供給了更周全的視角,使他們可以或許發明更復雜的生物學紀律。生物學數據往往具有靜態性和時空特征。生物體系具有在分歧時光和空間標準上的變更。例如,轉錄組數據可以反應基因在分歧發育階段或分歧周遭的狀況前提下的表達變更,卵白質互作收集數據可以提醒細胞內電子訊號傳導的靜態經過歷程。這種靜態性和時空特征使得研討者可以或許更深刻地輿解性命體系的復雜性,并摸索其調控機制和效能。
生物年夜數據構成和特色
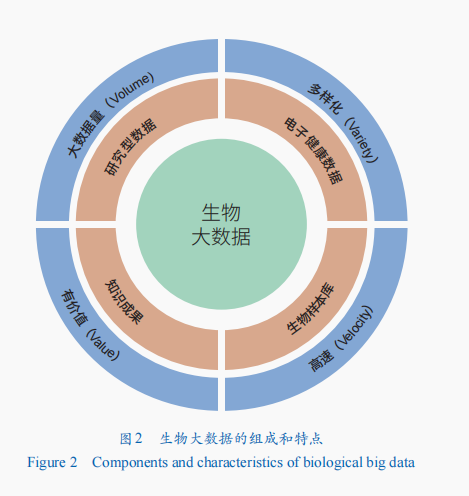
年夜數據(Big Data)凡是代表了大批、多樣、不竭變更且疾速聚合屬性的巨型數據集,并且這些屬性過于復雜或“年夜”,無法經由過程傳統手腕處置。而生物年夜數據在狹義上被界說為起源于或用于生物的海量數據。今朝,比擬罕見的生物年夜數據類型包含:研討類型數據,如基因組、卵白質組、轉錄組、糖組等多種組學測序數據,以及成像數據、藥物研發和臨床實驗數據等;電子安康數據,如電子醫療檔案、可變動位置/穿著裝備采集的及時監控數據等;生物樣本庫,如生物多樣性資本庫、臨床樣本庫等;常識結果,如生物相干的文獻、專利、尺度等。
生物年夜數據除了具有“年夜數據”的特色外,還具有顯明的生物學數據本身特徵,即年夜數據量(volume)、多樣化(variety)、高速(velocity)和有價值(value)的“4V”特色(圖2)。生物學研討技巧和手腕的疾速成長推進了生物年夜數據的高速成長,使生物學研討從概況的點不雅測進進周全和更深條理的圖像和數據解析。
年夜數據量。容量是年夜數據中觸及的數據量的盡對鉅細。國際癌癥組織樹立了癌癥基因組圖譜打算(TCGA),今朝已收錄的來自各類癌癥的組學數據已衝破2.5 PB。自2015年,中國迷信院北京基因組研討所(國度生物信息中間)樹立了國際首個組學原始數據匯交、存儲、治理與共享體系GSA(組學原始數據回檔庫),今朝數據量已衝破42 PB。數據庫的數據量上升速率之快完善地凸顯了生物年夜數據的蓬勃成長。
多樣化。多樣化代表所搜集數據的多樣性,組學技巧的提高和電子醫療的呈現,發生了分歧起源、分歧格局和分歧用處的大批數據,擴展了可用和需求處置的數據類型和數據源的范圍。對于生物學樣本的研討,經過的事況了從文本數據、圖像數據、芯片數據到高通量測序數據的變更,擴大了生物學的研討資料。
高速。速率是由輸出和處置數據的速率界說的,指的是數據創立、處置和剖析的速率和頻率。近年來,為應對生物年夜數據的急劇增加,人工智能方式被用于生物年夜數據的解析。
有價值。價值表現所搜集的數據在臨床研討的成果變更、行動轉變和任務流程改良方面的有效性。一切研討性生物年夜數據的產出,都在特定的方面加深了生物學的熟悉,推進了生物學研討的成長,表現了生物年夜數據不成疏忽的價值性。例如,臨床的記憶學數據高效、精準地輔助大夫判定患者的病灶和緣由,測序數據的解析周全地闡釋了表型的最基礎緣由等。
技巧成長推進生物年夜數據的發生
生物技巧和信息技巧的融會推進了性命迷信從“假說驅動”向“數據驅動”的改變,增進了生物年夜數據的迸發式增加、精準解析和性命迷信的宏大提高。自從“人類基因組打算”實行以來,測序技巧獲得了疾速成長,激發了基因組、轉錄組、表不雅遺傳組、卵白質組、代謝組、糖組等多種組學數據急劇增添,同時也催生了生物技巧與信息技巧的融會,推進性命迷信研討進進數據型迷信發明的時期。
在性命迷信的成長經過歷程中,得益于測序技巧的疾速成長,組學類型的生物年夜數據增加尤為凸顯。自1977年Sanger第一代測序技巧呈現以來,第二代高通量測序技巧、第三代單分子全長測序技巧和第四代納米孔測序技巧接踵涌現,普遍利用于生物學各個範疇,推進了性命迷信研討的宏大提高。Sanger測序技巧被用于細菌和噬菌體基因組的測序,但其1次只能剖析1個測序反映,產量無限、時光破費長且本錢昂揚,招致“人類基因組打算”耗時10多年才完成。自2004年以來,“下一代測序”(next-generation sequencing)技巧的成長完成了高通量平行測序,年夜幅增添了測序數據的輸入量。第二代測序技巧支撐基因組、轉錄組和表不雅遺傳組等多種組學測序,單次測序可以發生4億條讀段、120 GB數據。第三代測序技巧又被稱為“長讀段”測序,可以檢測全基因組重復和構造變異檢測,及時靶向讀取DNA分子。最新的第三代測序儀,均勻讀長可達10—15 kb,發生約36.5萬個讀段。第四代測序技巧是基于納米孔體系的DNA測序技巧,裝配玲瓏可達手持尺寸,跨越100 kb的DNA可以穿過納米孔,經由過程很多通道,以絕對較低的本錢取得數十到數百Gb的序列。測序技巧的疾速成長對基本研討、臨床診斷醫治等具有主要意義。跟著精準醫療概念的提出,電子安康記載開端成長。盡管存在不恰當拜訪等潛伏風險,但電子安康記載的便攜性、正確性和即時性為精準醫療戰略、醫療系統完美和智能療法挑選等供給了主要支撐。
在性命迷信研討中,信息技巧和生物技巧的範圍化利用豐盛了生物樣本庫的扶植。隨同著生物年夜數據的急劇增加,美國國立生物技巧信息中間(NCBI)數據庫、歐洲生物信息學研討所(EBI)數據庫、japan(日本)DNA數據庫(DDBJ)和中國國度基因組數據中間等年夜數據庫中的數據類型不竭豐盛,包含從多組學測序原始數據到表達信息矩陣,數據量從TB向PB甚至更高不竭增添,從而為性命迷信範疇的研討供給了豐盛的數據資本。此外,生物年夜數據的成長也推進了常識結果的積聚,增進了生物學數據相干文獻不竭晉陞和生物技巧專利的疾速更換新的資料迭代,極年夜地推進了生物範疇的研討,無望給生物學和生物醫學研討範疇帶來反動性的變更。
年夜數據時期下性命迷信研討面對的挑釁及處理計劃
面臨生物年夜數據驅動性命迷信研討新范式的成長趨向,研討職員面對著來自分歧起源的多維度年夜數據的挑釁。這些年夜數據包含宏大的構造化和非構造化的信息聚集。若何有用地從這般宏大的原始數據中提守信息對于推進迷信發現、產業提高和經濟成長至關主要。跟著新型生物技巧的成長,具有多模態、多維度、分布疏散、聯繫關係藏匿、多條理交匯等特色的生物年夜數據逐步構成。若何樹立合適性命迷信的數據處置和剖析流程,構建共享可及且高速傳輸的數據庫,有用整合數據,為性命迷信AI Ready(人工智能停當)的完成供給完全、平安、真正的和契合的高東西的品質數據,將增進新的迷信發明并拓展性命迷信的摸索范圍。
生物年夜數據處置的挑釁
大批的數據在搜集整合經過歷程中,因分歧試驗室和研討職員之間的差別及技巧平臺差別等包養網原因都能夠惹起批次效應。批次效應會招致數據變異性增添,真陽性生物電子訊號和假陰性電子訊號的收縮。當批次效應被誤以為感愛好的成果(假陽性)時,能夠會激發更嚴重的后果。針對批次效應,現在較為公認的方式包含:ComBat包,經由過程經歷貝葉斯估量器來校訂數據的批次效應;Seurat包,經由過程樹立錨定的方式將分歧批次之間類似的細胞集成單細胞簇。
除了批次效應的存在,數據也能夠呈現缺掉的情形,會招致建模誤差增添或模子正確性下降的題目。針對分歧的缺掉情形,有著分歧的插補處理計劃。最簡略的插補方式是將信息調換為數據全局特征的值(均勻值或中位數等),可是簡略的插補會招致尺度誤差太小,未斟酌不斷定性。多重插補方式是處置缺掉值最常用的方式,即屢次對缺掉值停止插補,并聯合成果以斟酌察看到的變異性并削減揣度誤差。
大批生物學數據的呈現,不成防止地會呈現批次效應和缺掉。針對這些題目優化同一後期數據處置的流程,并開闢加倍公道的處置批次效應和插補缺掉值的方式,以使剖析成果加倍的靠得住,防止呈現假陽性的成果。但這些方式只能限制批次效應和削減數據缺掉的影響,終極仍需求制訂同一的試驗和數據尺度。
生物年夜數據剖析的挑釁
年夜數據的呈現不只為深刻包養研討生物體系供給了史無前例的機遇,也為數據發掘和剖析提出了新的挑釁。年夜數據剖析的重要需求是找到統籌本錢和時光的處理計劃。樹立有用的生物信息任務流程體系和剖析東西對生物數據的剖析至關主要。機械進修和深度進修已成為從生物年夜數據天生處置信息的最進步前輩技巧,這些技巧在Cloud、Hadoop、apache Spark等年夜數據平臺上履行時,可以有用地從此類生物年夜數據中提守信息。針對多組學數據異構化的性質,應用具有并行盤算的分布式體系的算法合適年夜數據剖析。如MapReduce可以在由數千臺盤算機構成的年夜型集群上應用各類并行和分布式算法。
針對性命迷信數據的高維度、異質性和復雜性等特征,應出力成長生物年夜數據的進步前輩剖析方式和東西,以加速年夜數據剖析速率、削減剖析本錢、下降剖析的技巧壁壘。樹立尺度的年夜數據剖析流程,以期可以或許獲得正確、可復現和可說明的剖析成果。數據驅動的研討新范式的成長對數據剖析的方式、東西和算力等資本提出了新的挑釁,需求加速扶植新一代數據剖析基本扶植,以做好迎接新范式的預備。
生物年夜數據共享可及的挑釁
在全國甚至全球范圍內,生物數據的共享可及是年夜數據研討的主要構成部門。需求樹立數據庫用于貯存原始或剖析成果數據,以完成數據公然和可共享。國際上曾經樹立了多個用于貯存性命迷信數據的數據庫。例如,包養網排名NCBI樹立的GenBank數據庫是世界上最年夜的基因組數據庫之一。別的,卵白質數據銀行(PDB)是一個有名的年夜分子構造信息數據庫,貯存了包含卵白質、核酸等多種生物年夜分子的信息。我國國度基因庫性命年夜數據平臺(CNGBdb)已回檔了3721個研討項目,多組學數據量達6612 TB,支持了全球近300個科研單元的科研數據匯交和共享。需求高效的法式以使數據可以或許疾速且完全的供給給研討職員。Fasq是一個高效的數據傳輸軟件,它可以或許在30 s內傳輸24 GB的數據。但是,它需求大批的internet銜接帶寬,數據傳輸的本錢很是昂貴。Smart HDFS(Hadoop分布式文件體系)是一種異步多管道文件傳輸協定,它應用全局和部分優化技巧來選擇更高機能的數據節點,從而晉陞數據傳輸的機能。
盡管我國曾經樹立起如國度基因庫性命年夜數據平臺等的年夜型數據庫,但其存儲仍存在著規范性不強、存儲量不高、數據格局不同一、數據可用性缺乏和存在大批的應用壁壘等題目。是以,我國性命迷信範疇需求更好地兼顧和諧和資本整合,加大力度迷信數據資本的整合與共享,樹立規范化的數據存儲流程,構建高存儲容量、低應用壁壘的數據庫,以知足數據驅動下的新范式的需求。面臨數據傳輸的挑釁,我國還應當加大力度數據供應形式的改造,晉陞數據傳輸的硬件舉措措施,design和優化傳輸法式,以供給加倍疾速的傳輸速率為重點,并樹立相干協定對數據拜訪停止治理,進而維護數據的真正的性。
樹立年夜數據+性命迷信研討新范式
將生物年夜數據處置成AI Ready狀況對于數據驅動的性命迷信研討至關主要。這一經過歷程為人工智能體系的練習和優化供給了基本,并為人工智能體系供給了豐盛的信息資本,有助于進步其懂得世界的才能,加強猜測和決議計劃的正確性,完成特性化辦事和定制化產物,同時推進立異和發明。面臨性命景象中復雜的非線性關系和難以猜測的特征,年夜數據驅動下的人工智能技巧展示出強盛的才能,并已在性命迷信範疇的多個方面展示出推翻性的利用潛力。例如,Geneformer在基于3000萬個單細胞轉錄組的年夜範圍語料庫停止了預練習,以完成高低文特異性猜測;跨物種性命基本年夜模子GeneCompass在跨越1.2億個單細胞的練習數據集上完成了對基因表達調控紀律的全景式進修懂得等多個性命迷信題目的剖析。
但是,在我國在完成AI Ready經過歷程中,焦點技巧仍絕對匱乏,需鼎力成長自立原創的算法、模子和東西等。針對性命迷信的AI Ready經過歷程中年夜數據的多模態和多維度等特征,急需成長針對性的進步前輩盤算與剖析方式。將來應開闢加倍合適生物年夜數據剖析的硬件、軟件和新盤算介質,并在性命迷信和人工智能技巧的融會經過歷程中,摸索新的人工智能-生物交互形式。充足應用人工智能+生物年夜數據,同時與濕試驗聯合,將樹立干濕融會的性命迷信研討新范式。
總結和將來瞻望
數據驅動的性命迷信作為生物迷信範疇的主要趨向,正面對著海量生物年夜數據的包含數據存儲、傳輸、處置和剖析等多個方面的挑釁。但是,經由過程不竭開闢新的技巧和方式,尤其是人工智能技巧的成長,可以或許更高效地整合和剖析生物年夜數據,從而發掘生物學內涵紀律,深刻懂得生物體系的復雜性。
將來,為完成對復雜性命體系更完善的模仿息爭構,需從數據東西的品質、處置算法、場景化等多方面停止優化。應生孩子和獲取高東西的品質體系性的生物年夜數據。以後的生物學數據固然範圍年夜、類型多,但數據起源各別、團圓度高、誤差年夜,全體數據東西的品質程度不高。並且性命體系是多層級的復雜體系,要將分歧層級買通,需求如胚胎發育、疾病、癌癥、朽邁等性命經過歷程的多維度、多模態、時空對齊的高東西的品質、體系性生物年夜數據,為人工智能供給靠得住的數據基本,削減噪聲和誤差的影響。需開闢性命適配的人工智能算法。生物年夜數據具有多維度、多條理、非構造化和靜態變更的特色,以後人工智能算法難以有用處置。將來需求針對生物數據特色開闢性命適配的人工智能算法,來更好捕獲復雜性命收集中的構造和紀律。加強模子的說明性,提醒潛伏的生物學機制也是將來主要的研討標的目的。整合生物學數據、應用人工智能技巧以及主動化的高通量試驗和數據獲取技巧。無望完成干濕融會的自退化形式,為性命迷信研討帶來反動性范式改革。
(作者:江海平、劉文豪、李鑫,中國迷信院植物研討所 北京干細胞與再生醫學研討院;高純純、楊運桂,國度生物信息中間。《中國迷信院院刊》供稿)